DeepSeek令人驚訝的是,廉價的AI模型挑戰了行業巨頭。該公司聲稱已經培訓了其強大的DeepSeek V3神經網絡,僅利用2048 GPU,這與競爭對手的成本明顯更高。但是,這個數字具有誤導性。
DeepSeek的自我引言:“嗨,我是被創造的,所以您可以問任何問題並得到一個甚至可能會讓您感到驚訝的答案,”該模型的功能暗示了Nvidia的股票價格大幅下降。該模型的成功源於創新技術:
- 多語預測(MTP):同時預測多個單詞,提高準確性和效率。
- 專家的混合物(MOE):使用256個神經網絡,每個令牌激活8個,加速培訓和性能。
- 多頭潛在注意力(MLA):反複提取關鍵細節,最大程度地減少信息丟失並增強細微差別的理解。
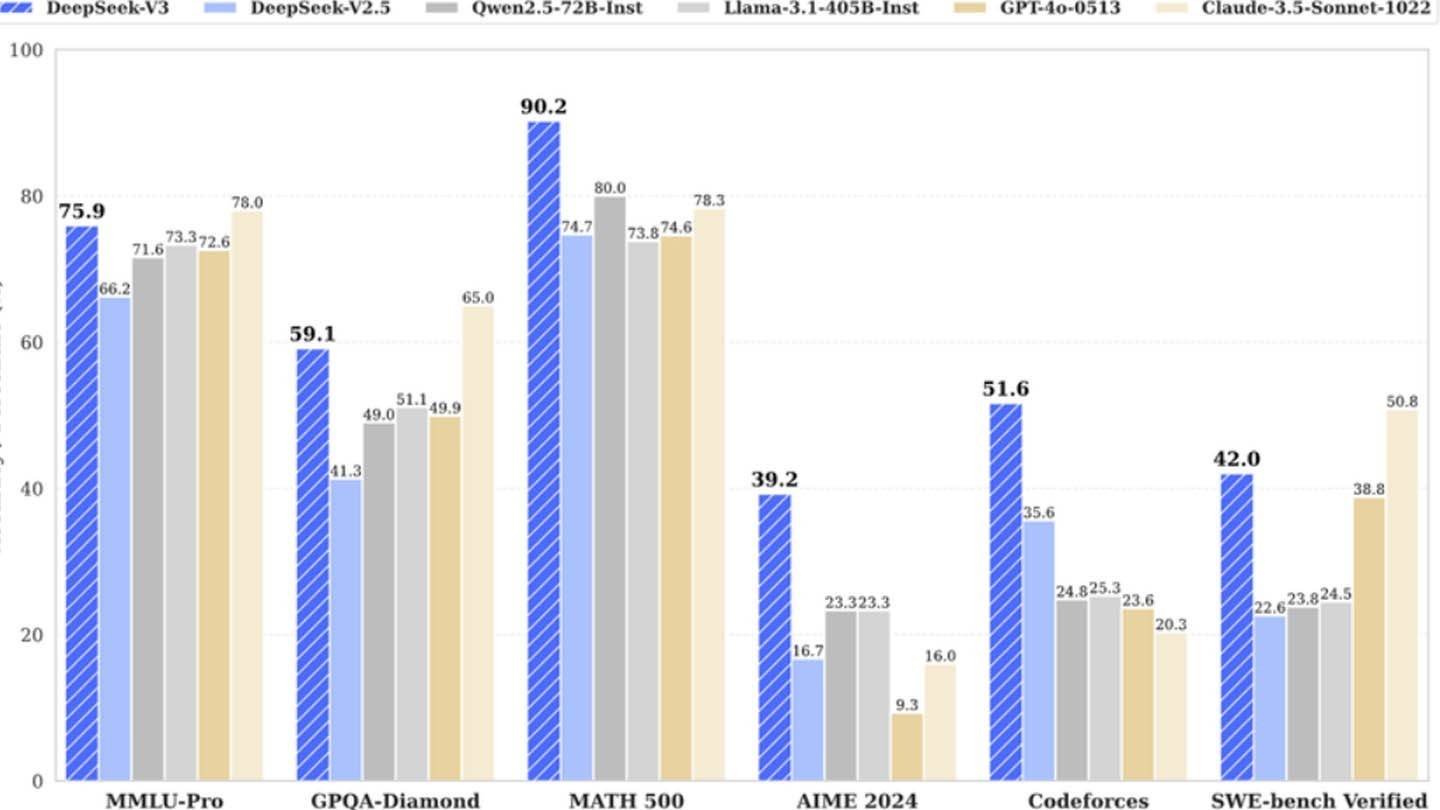 圖像:ensigame.com
圖像:ensigame.com
盡管培訓成本較低,但一份半分析報告揭示了DeepSeek的大量基礎設施:大約50,000個NVIDIA HOPPER GPU(包括H800,H100和H20單位)分布在多個數據中心,成本約為16億美元。運營費用估計為9.44億美元。
 圖像:ensigame.com
圖像:ensigame.com
中國對衝基金High-Flyer的子公司DeepSeek擁有其數據中心,與雲依賴的競爭對手不同。這提供了更大的控製和更快的創新。該公司的自籌資金促進了敏捷性。高薪(對於一些研究人員來說,每年超過130萬美元)吸引了中國頂級人才,不包括外國專家。
 圖像:ensigame.com
圖像:ensigame.com
這筆600萬美元的數字僅涵蓋培訓前的GPU使用情況,不包括研究,改進,數據處理和基礎架構。 DeepSeek的總AI投資超過5億美元。它的精益結構有助於有效的創新。
 圖像:ensigame.com
圖像:ensigame.com
DeepSeek的成功表明了一家資金充足的獨立AI公司與知名球員競爭的能力。但是,其“預算友好”的主張被誇大了。數十億美元的投資,技術突破和強大的團隊是關鍵因素。對比是鮮明的:DeepSeek的R1耗資500萬美元,而Chatgpt-4的成本為1億美元,突出了巨大的成本差異。盡管提出了誇張的說法,但DeepSeek的成本仍然大大低於其競爭對手。













